A physics-informed neural network method for solving parametric differential equations
We present a novel, accurate, fast, and robust physics-informed neural network method for solving problems involving differential equations (DEs), called Extreme Theory of Functional Connections, or X-TFC. The proposed method is a synergy of two recently developed frameworks for solving problems involving DEs: the Theory of Functional Connections TFC, and the Physics-Informed Neural Networks PINN. Here, the latent solution of the DEs is approximated by a TFC constrained expression that employs a Neural Network (NN) as the free-function. The TFC approximated solution form always analytically satisfies the constraints of the DE, while maintaining a NN with unconstrained parameters. X-TFC uses a single-layer NN trained via the Extreme Learning Machine (ELM) algorithm. This choice is based on the approximating properties of the ELM algorithm that reduces the training of the network to a simple least-squares, because the only trainable parameters are the output weights. The proposed methodology was tested over a wide range of problems including the approximation of solutions to linear and nonlinear ordinary DEs (ODEs), systems of ODEs, and partial DEs (PDEs). The results show that, for most of the problems considered, X-TFC achieves high accuracy with low computational time, even for large scale PDEs, without suffering the curse of dimensionality.
X-TFC Solutions of Differential Equations
Differential Equations are a powerful tool used for the mathematical modelling of various problems arising in scientific fields such as physics, engineering, finance, biology, chemistry, and oceanography, to name few. We can express DEs, in their most general implicit form, as
$$ \gamma f_t + \mathcal{N}\left[f;\lambda\right] = 0 $$
subject to certain constraints, where \( f(t,x) \) represents the unknown solution, \( \mathcal{N}\left[ f ; \lambda \right] \) is a linear or nonlinear operator acting on \(f \) and parameterized by \( \lambda \), and the subscript \( t \) refers to the partial derivative of \(f \) with respect to \(t \).
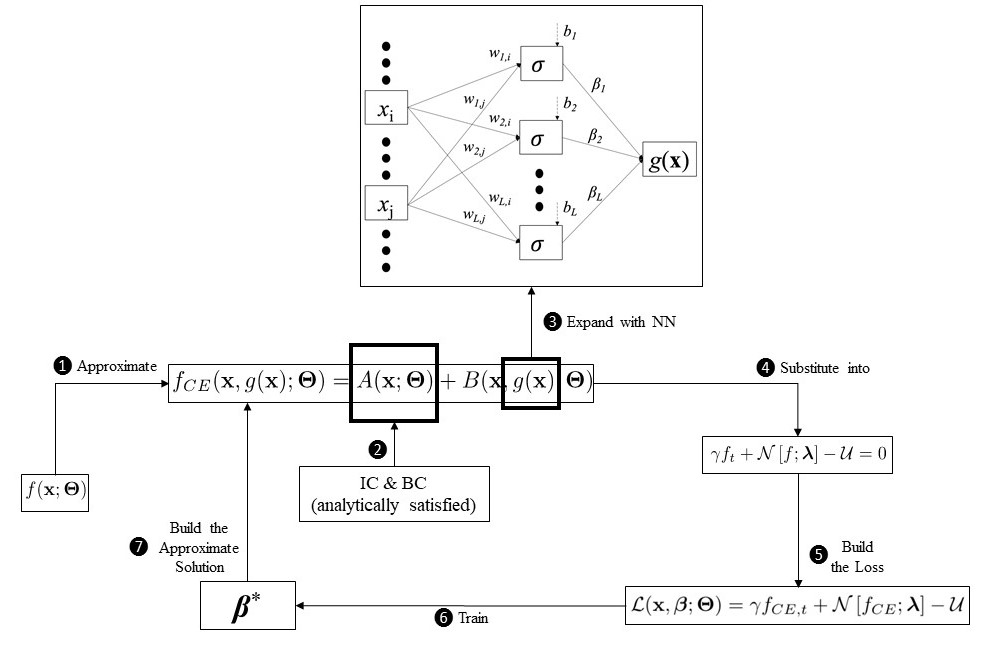
The first step in our general physics-informed framework is to approximate the latent solution \(f \) with a constrained expression that analytically satisfies the constraints as follows
$$
f(x; \Theta ) = f_{CE}(x, g(x); \Theta) = A(x; \Theta) + B(x, g(x); \Theta)
$$
where \(x = [t,x]^T \in \Omega \subseteq \mathbb{R}^{n+1}\) with \(t \geq 0\), \(\Theta = [\gamma, \lambda]^T \in \mathbb{P} \subseteq \mathbb{R}^{m+1}\),\(A (x; \Theta)\) analytically satisfies the constraints, and \(B(x, g (x); \Theta)\) projects the free-function \(g(x)\), which is a real valued function, onto the space of functions that vanish at the constraints. According to the X-TFC method, the free-function, \(g(x)\), is chosen to be a single layer feed forward NN, in particular, an ELM, that is
$$ g(x) = \sum_{j=1}^{L} \beta_j\sigma \left(w_j^Tx + b_j \right) = [ \sigma_1,...,\sigma_L ] \, \beta = \sigma^T \beta $$
where \(L\) is the number of hidden neurons, \({w}_j\) is the input weights vector connecting the \(j^{th}\) hidden neuron and the input nodes,
\(\beta_j \) is the \(j^{th}\) output weight connecting the \(j^{th}\) hidden neuron and the output node, \(b_j\) is the threshold (aka bias) of the \(j^{th}\) hidden neuron, and \(\sigma(\cdot)\) are activation functions. Both weights and bias are previously randomly selected, according to the ELM algorithm.
The figure below shows the schematic of the physics-informed X-TFC framework to solve forward problems involving parametric DEs.
Example (Non-linear 2D PDE)
The problem consider as first example is the following PDE
$$
f_{xx} (x,y)+f_{yy} (x,y) + f(x,y) f_y(x,y) = \sin(\pi x) \left(2 - \pi^2y^2 + 2y^3 \sin(\pi x)\right)
$$
where \(x,y \in [0,1]\) and subject to,
$$
f(0,y) = 0
$$
$$
f(1,y) = 0
$$
$$
f(x,0) = 0
$$
$$
f_y(x,1) = 2\sin(\pi x)
$$
which has the true solution \(f(x,y) = y^2 \sin(\pi x)\).
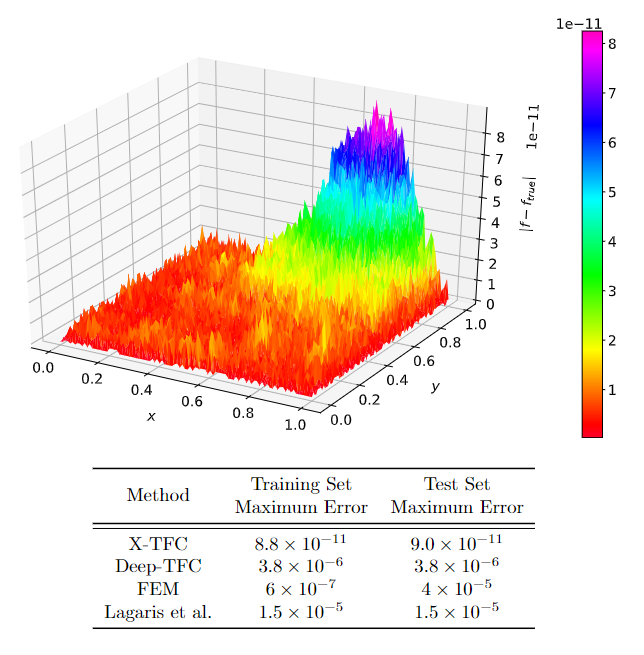
For this problem, the free-function was chosen to be an ELM with 150 neurons that used tanh as the activation function. The problem was discretized over \(20 \times 20\) training points that spanned the domain, and each iteration of the nonlinear least-squares was solved using NumPy's lstsq function. The total execution time was 22.48 seconds, and the nonlinear least-squares, which needed 10 iterations, took 52.6 milliseconds. In addition, the training set maximum error was \(7.634\times10^{-11}\), and the training set average error was \(9.497\times10^{-12}\). The test set maximum error was \(8.977\times10^{-11}\), and the test set average error was \(1.068\times10^{-11}\); the test set was a \(100\times100\) grid of uniformly spaced points.
The following figure summarizes the results of this example.
Figure (top) illustrates that the solution error is lower near where constraints are defined on the boundary value than where they are defined on the derivative, because the TFC constrained expressions guarantees there will be no error in the solution value for constraints defined on the boundary. Table (bottom) shows that the X-TFC method outperforms all other methods in terms of accuracy by 4 to 6 orders of magnitude.
Example (Non-linear 3D time-dependent PDE)
The second numerical example proposed here is a non-linear 3D and time-dependent PDE provided with analytical solution \(f(x,y,z,t)\) . The PDE is in the form
$$
f_x f_y f_z + f_{tt} = \left((t-1)tx(z-1)+x^2\cos(x^2y) + \frac{3}{2}x\sqrt(y)z\right) \left((t-1)ty(z-1)+2xy \cos(x^2y) + y^{3/2} z\right)
$$
$$
\left( 2\pi t^2 \cos(2\pi z) + (t-1) txy + xy^{3/2} \right) + 2xy(z-1) + 2 \sin(2 \pi z)
$$
where \(x,y,z,t \in [0,1]\), and subject to the following constraints
$$
f(0,y,z,t) = t^2 \sin(2\pi z)
$$
$$
f(x,0,z,t) = t^2 \sin(2\pi z)
$$
$$
f(x,y,1,t) = \sin(x^2y) + x \sqrt{y}
$$
$$
f(x,y,z,0) = \sin(x^2y) + x \sqrt{y}z
$$
$$
f(x,y,z,1) = \sin(x^2y) + x \sqrt{y}z + \sin(2\pi z)
$$
whose analytical solution is
$$
f(x,y,z,t)=t^2 \sin(2\pi z) + \sin(x^2y) + xy^{3/2}z + xyt(z-1)(t-1)
$$
For this problem, the free-function was chosen to be an ELM with 340 neurons that used tanh as the activation function. The problem was discretized over \( 5 \times 5 \times 5 \times 5\) training points that spanned the domain, and each iteration of the nonlinear least-squares was solved using NumPy's lstsq function. The total execution time was 321.9 seconds, and the nonlinear least-squares, which needed 10 iterations, took 0.229 seconds. Additionally, the training set maximum error was \(2.744\times10^{-5}\), and the training set average error was \(6.641\times10^{-7}\). The test set maximum error was \(2.978\times10^{-5}\), and the test set average error was \(8.082\times10^{-7}\); the test set was a \(10\times10\times10\times10\) grid of uniformly spaced points.